

I’m going paperless with all those pieces of paper in file folders.
It’s time to manage digitally the documents, invoices, statements, etc. that I get. It may take awhile, but I’ll get to an organized database of PDF files largely replacing files in folders in a file cabinet.
I’ve been scanning paper documents out of the file cabinet to PDF files and then shredding them.
And I’ve been pulling together documents I have in digital format into a new central location with a defined structure.
Here are the tools I’m using:
- An HP OfficeJet combo printer for scanning paper to PDfs in a network folder. (For files too large or odd shaped for the HP, I’m using the free version of the Swiftscan phone app, which I have set to save documents to Google Drive.)
- Pandocto convert Word, text or markdown documents to PDFs. For spreadsheets, I just open them in Google Sheets and export as PDF. (I don’t have a lot of spreadsheets.)
- ExifTool for adding metedata.
- QPDF to handle PDFs or pages in PDFs that need rotating, added or split.
- Paperless-ngxas the database for my PDFs. It is running in a docker container on my QNAP NAS.
- Amazon Basics shredder to get rid of the paper.
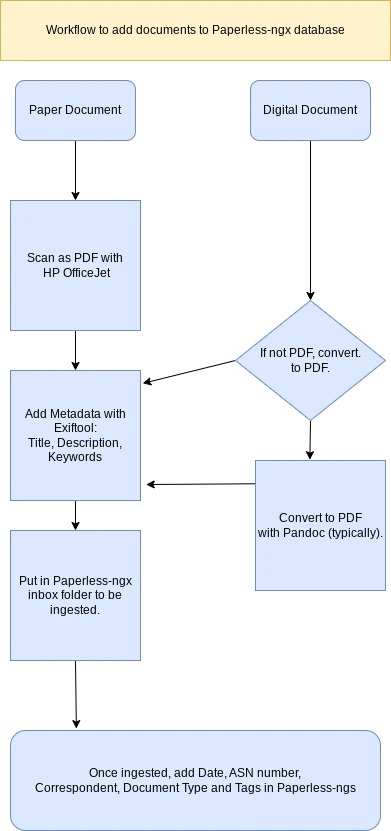
Here is a simplified drawing of the workflow.
Using ExifTool is an optional step with Paperless-ngx, but I’m using it to ensure portability of the PDFs.
If I move on from Paperless-ngx, my documents will still have the metadata that I added with ExifTool. Paperless-ngx uses most of that data as well. I add title, description (or subject) and keywords with ExifTool and then move the document to Paperless-ngx.
QPDF is not used that much in this workflow, but occasionally I will scan a document upside down and need to rotate it. Or a wide document has to be scanned vertically and then I’ll rotate it back to horizontal with qpdf to make it easier to read.
Pandoc, ExifTool and qpdf are run from the command line in the linux container in my Chromebook.
I have Paperless-ngx set to store the PDFs in a hierarchy of “Corespondent” and then “Year.” It stores both the original and an “archive” PDF/Aversion in matching trees.
So, for example, my tax forms go in the IRS folder with each year having its own subfolder under the IRS folder.
Paperless-ngx also have an export feature for that creates a third copy with a json file of the data from its database. (And, of course, you need to follow good backup strategies for the NAS.)
The Paperless-ngx web interface gives a quick way of searching for documents in various ways including from free-form text searches to its tag, document type, correspondent and date fields. It’s a powerful tool being actively developed and supported on Github.
In my setup, Paperless-ngx only runs locally and is not exposed to the public internet, but it’s mobile friendly, so I can pull it up on my phone if I’m on my home network.
QNAP also has a search engine called Qsirch that works much like a local Google on the NAS files.
Will I get rid of the file cabinet completely? Not likely, but I will be opening it less and less.
An added benefit is I was storing a lot of paper I just didn’t need. This has forced a “toss-it or keep-it” decision with “toss-it” often winning.
There are certainly other ways to accomplish the goal of the paperless home office, but I hope this post sparks some ideas.
(File folder image via Pixnio.com. Workflow drawing created at diagrams.net.)